What if we used Jupyter as a SOAR?
Today, rightfully, all the rage is on XDR and the broken promises of SOAR and I fully support that feeling: your mileage may vary but, from my experience, developing something sustainable within a SOAR is an endeavor:
- Runtime dependency is a nightmare: this playbook requires this version of this third-party Python library while another playbook wants another version, the deployment and management of dependencies is YOLO
- No failure domain isolation: one playbook can impact the global platform because of a syntax error, there is no concept of isolation (who said container?)
- The 80s called, and they want their development practices back: There is no versioning, there is no audit-ability of a playbook updated in the UI
- The SOAR is not at the service of the analyst but more the opposite: An analyst is not empowered to modify a playbook: They can only use whatever was given to them by their BUILD team.
- Unscoped platform: Should the SOAR do the case management? Ticketing system? Or should it be an orchestration-only platform?
Instead of adopting a new way of working, what if we tried to compose with already existing basic bricks to implement something similar? Yeah I know it sounds boring but that’s usually the best way to succeed.
The lingua franca of Infosec is probably Python, and the best way to use it collaboratively is Jupyter(Hub). Let’s experiment with that!
JupyterHub as a SOAR
The detection rules are stored in Splunk as Saved Searches, they generate Notable Events on matches.

Dispatcher notebook
Independently, a cron task executes papermill every minute, it instantiates the dispatcher Jupyter notebook:
- It fetches the notable events that were generated the minute before
- For each notable event:
- We retrieve the context of the alert
- which detection strategy matched?
- what is the source type of the matching event?
- what is the SPL that matched?
- Based on the context, we try to identify and instantiate a specialized Jupyter notebook to process this alert. If not, we instantiate a generic Jupyter notebook.
- Once the notebook’s execution is finished, we send an email to the incident analyst’s team (ticketing system) with a link to the Jupyter notebook.
- We retrieve the context of the alert
Why use a Jupyter notebook to do this dispatching? Because it is very practical to see exactly what happens when there is an exception or error somewhere, debugging is much much easier.
Specific investigation notebook
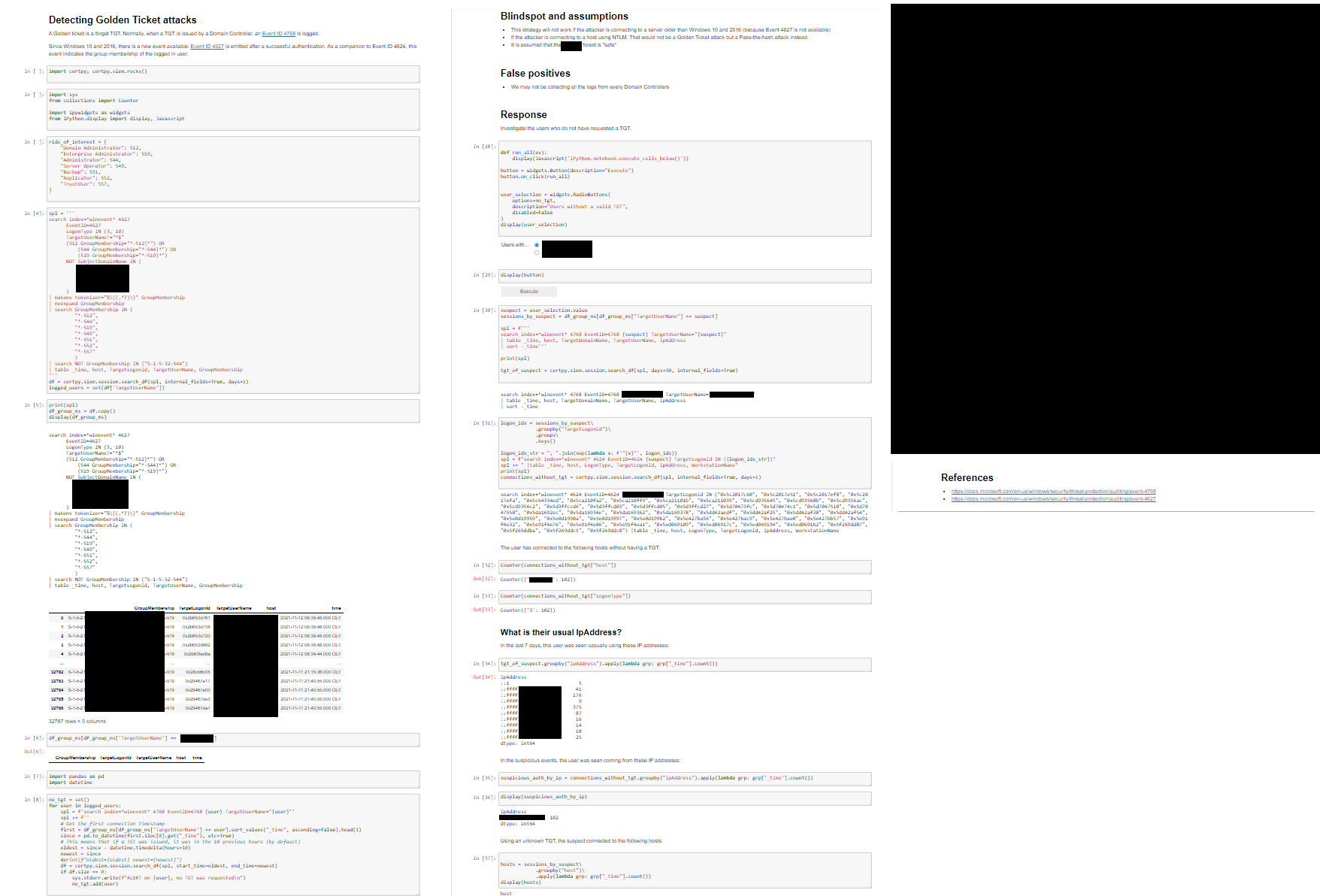
When the Incident Analyst receives the ticket, they access to the collaborative JupyterHub instance and can immediately review the playbook from their Web browser:
- The playbook follows the structure of the Palantir Alerting and Detection Strategy Framework, this means the analyst has the whole context behind the detection, and the Response section is implemented directly in the notebook (in Python)
- If the predefined Response is not enough, analysts are free to modify the Jupyter Notebook and perform their queries accordingly. As long as everything is done in the notebook, everything is tracked and auditable. At this point, all the changes are local to this specific case, if the analyst thinks there is room for improvement for future alerts:
- They can commit the changes to the “referential Jupyter notebooks repository” using the classic Github workflow.
- They send a link of this specific investigation notebook to the BUILD team for inspiration. They will be able to see exactly how the analyst resolved the investigation and what is missing from the “reference notebook”.
From here, the sky is the limit, it is not implemented yet, but we could imagine more follow-up actions like closing and commenting the case in the ticketing system from the notebook automatically. Thanks to the richness of Jupyter’s widgets, it is easy to implement user-friendly actions.
This way of working is also a forcing function to implement as much Python as possible, in this frame, my team developed a Python library called certpy that is the API of the team: every tool used is interfaced in this library and its input and output are consistent along with the different modules.
Conclusion
Full disclosure: I will not lie, this is not running in production even though everything is 💯 functional. Why? Moving to this architecture is a massive change of paradigm to the current teams (60+ people), and making the move would require a lot more investment in the current toolings.
I truly believe in this solution, it is simple and elegant without twisting each of these tools. Furthermore, it doesn’t require a heck of a platform stack: install JupyterHub and you are good to start!
From the human point of view, it only requires the analyst to know a bit of Python, no need to learn a new framework. The interfaces with other SOC tools are made possible thanks to the work of a good internal engineering team developing a SOC library.